Quite a while ago I was implementing an interpreter. A common task in the interpreter is to select the correct interpreter function based on the type of the input. Let’s say we want to implement an addition. We might end up with something like below:
to implement the operation. At runtime, we want to dispatch to the right function base on the type of the operands. A natural way to do this is to have a static array holding the mapping from the operand type to the function pointer, similar to below:
so at runtime we can just read x_addOpPtr[operandType] to obtain the function pointer we want to call.
The X Macro
Although the code above can work, it is clearly too error prone. If we accidentally made a mistake in the order of the list, we are screwed. A better way is the X Macro pattern. We define a “X macro” for all the types:
Then, by defining what X(EnumType, CppType) expands to, we can create logic based on our needs. For example, the following code would reproduce the x_addOpPtr array we want:
Unlike the addition operator, now we have two types Src and Dst to enumerate on, so we have to generate a two-dimensional array. While X Macro can easily iterate through one list and perform action on every item, it cannot iterate through the Cartesian product of two lists. A worse solution, is of course, to manually define a list containing all the <Src, Dst> pairs, so we can do X macro again. But what if we want to do a three-dimensional Cartesian product in the future?
After some fruitless Googling and home-making attempts to build a “two dimensional X Macro”, I eventually gave up and switched to an ugly solution. Instead of generating a clean static array, we generate a tree of templated dispatching functions. The function at the i-th level use a dispatch array (built by X macro) to dispatch to the next level’s selector function based on the i-th parameter type. We get the function pointer when we reach the leaf. While this approach works, no doubt it is very ugly, and probably also less performant (I didn’t check if the C++ compiler were able to optimize away all the terrible things).
The FOR_EACH Macro
I used to believe my ugly solution is as good as one can get without resorting to manually enumerating the Cartesian product. However, today I learnt an interesting approach from David Mazieres, which he calls the FOR_EACH macro.
The semantics of the FOR_EACH macro is pretty clear. Taking a macro X (similar to the X in X Macro) and a comma-separated list of elements e1, e2, ... , en, the FOR_EACH macro invokes X on each e in the list. For example, the addition example would look like:
1 2 3 4 5 6 7 8 9 10 11 12
// Note that the 'X' is gone, and the list is comma-separated #define TYPE_LIST \ (Int32, int32_t) , \ (Int64, int64_t) , \ (Double, double_t) ... #define X(e) (void*)Add<TUPLE_GET_2(e)> , staticvoid* const x_addOpPtr[] = { FOR_EACH(X, TYPE_LIST) nullptr }; #undef X
The most important difference between FOR_EACH macro and X Macro is that the FOR_EACH list definition doesn’t take X. Unlike the X Macro, where the macro to call on each element is hardcoded to only pass the element itself, the FOR_EACH macro decoupled “the element to be processed” and “the macro processing the element”. This removes the biggest blocker to implement a macro that can enumerate through Cartesian product of multiple lists.
The core of the trick which allows FOR_EACH’s list definition to get rid of the X lies in the C++20 new feature__VA_OPT__. David Mazieres’ original article is already a good explanation on how the FOR_EACH macro works so I won’t parrot it again. With the main blocker removed, after only a few hours of work, I was able to successfully extend FOR_EACH to support enumerating through the Cartesian product of multiple lists. (By the way, even after implementing it, I still have very little idea on how the C preprocessor works, but clang++ -E is enough to trial-and-error into a working solution).
The FOR_EACH_CARTESIAN_PRODUCT Macro
I call my macro FOR_EACH_CARTESIAN_PRODUCT. As the name suggests, it takes a macro X and one or more lists (L1), ..., (Ln). Then for each (e1, ..., en) in the Cartesian product L1 x ... x Ln , the macro X(e1, ..., en) is invoked. The elements in the Cartesian product are enumerated in lexical order.
For example, for the type-casting example above, the below code would construct our desired two-dimensional dispatch array:
Note that the generated array is one-dimensional, but indexing it is pretty simple: x_castOpPtr[opType1 * numTypes + opType2] will give us the desired function pointer for Src=opType1 and Dst=opType2.
The code, which contains both the implementation for FOR_EACH_CARTESIAN_PRODUCT and the above examples can be found here. The code is in public domain so feel free to use.
Recently I attended the OOPSLA 2021 conference. While I haven’t barely learnt anything from the conference itself, it’s indeed a break from my routine life, and I have probably met more people than the sum of the past few months. So as a result, I had some random thoughts and reflections, which I decide to take notes here before they disappear.
Methodology of Decision Making
It is well known that one should not judge a decision based on its outcome, because we cannot have full awareness of the world (so there are information that we cannot know beforehand), and the world itself also contains many random factors (so we cannot predict the future even with complete information). Therefore, an undesirable outcome does not imply the original decision is wrong or improvable.
However, humans are born irrational. Many never understand the above argument at all. But even within the people who can recognize it, I have seen (on both myself and others) many cognitive pitfalls when applying the argument.
Pitfall #1. Only apply when things go wrong. Ego makes people believe in their own decisions. So when things work out, it’s easy to overlook the possibility that the success is only coincidental and the original decision is unjustifiable.
As an extreme example, winning a lottery does not justify the decision of spending large amounts of money buying lotteries (which has a negative expected gain).
Pitfall #2. Overlooking the information one can know. Similarly, due to people’s ego, when something fails, it’s easy to use the argument as an excuse to deny responsibility, not realizing that the original decision could have been improved with more investigation and reasoning.
The most obvious examples are decisions made through overconfidence and negligence.
Pitfall #3. Overlooking the information one cannot know. As stated earlier, one cannot have complete information of the world, so that “there are information that one cannot know” is also an information that must be considered in decision making.
Examples of this pitfall are “perfect plans” that are designed without backups and leaves no buffer on accidents and errors.
So in short, one should not judge a decision based on its outcome, be it desirable or not; one should judge a decision based on the justifiability of how the decision is reached.
(Interestingly, everything stated above can also be observed in Japanese Mahjong)
Methodology of Becoming Productive Researchers
I am aware that all my research ideas have been produced by pure luck. If one had rewinded time, I’m very doubtful if I could come up with the same ideas again. And I feel it clueless to figure out the “next idea” like some of the PhD students who are more “on the right track” could easily do. So I have been curious how the professors can generate an endless stream of ideas for papers. I happened to have discussed this topic with two professors, so for future reference, I take notes here based on my memory.
Q1: (The context here is theoretical computer science.) The difficulty of figuring out a proof is probably exponential to the number of the steps in the proof. So how can you and your group produce so many long (>50 pages) papers every year?
A1 (Richard): We are not going for particular problems. Instead, we have a set of powerful math tools as building blocks, and we just build things up by gluing the blocks together, without a particular goal in mind. If at some time we found that the thing we built solved some problem, we have a paper. It’s like a naval battle: you don’t search for and destroy a particular ship (problem) on the sea. You patrol the sea and destroy any ship spotted along the way.
Q2: But I assume you still have some intuition on what might work and what might not. What is the intuition that guides you and how did you get this intuition?
A2 (Richard): I don’t know. It’s like the first man who figured out they can put guns on ships.
Q3: (The context here is PL/Compilers, and my advisor primarily works on sparse tensor algebra.) I asked my advisor how he could always have the next paper idea to work on.
A3 (Fred): There are many solved problems in the dense algebra domain, but little is known about the sparse algebra counterparts. TACO is a framework for solving problems in the sparse algebra domain, so it opens up a sequence of works by porting the solved problems in dense algebra to sparse algebra.
What Prevents Constructive and Rational Discussion?
The motivation of this part is the (still ongoing!) Chinese Internet shitshow centered around a consipracy theory that the Grand Final match of Dota2 TI10 is fixed.
I have never held any expectation on the rationality of the mass public, but I’m still astonished by that a conspiracy theory without even a self-coherent story can get dominance in the Chinese Dota2 community.
Though it might be my illusion, but I do feel the Internet discussions I see on contemporary matters have been getting increasingly polarized / emotion-driven, and decreasingly constructive / helpful in the past years. Is the mass public becoming more irrational? I don’t know. But after thinking for a bit, I do feel there are a few contributing factors.
It takes much more words and time to refute a conspiracy theory or to post some serious discussion, than to propose a conspiracy theory or to post some trashtalk.
The bandwidth of the Internet has greatly increased, but the bandwidth of the useful information being carried has actually decreased. On one hand, blogs are replaced by tweets, texts are replaced by pictures/videos, so the mass public has been trained to only read short messages, not serious discussions. On the other hand, mobile phones, which are not even designed to type efficiently, have surpassed the market occupation rate of PCs long ago, so it is also harder for the mass public to publish anything other than short messages. So the mass public has been trained to only read 140 characters and post 140 characters, not any serious discussions.
By Pareto principle, 80% of the voice in a community comes from 20% of the people. And the people who feel most compelled to speak out are usually the people holding the most extreme opinions. But under the current shape of the Internet, where serious discussions are unfavored, the megaphone is handed over to the most irrational ones, not the most rational ones.
The ranking mechanism, where contents are ranked by user votes and shown to users by rank, served as another amplifier.
But what about the POLs? Will they send out rational messages and lead the public opinions to the rational side? Unfortunately, at least for the Chinese Internet’s status quo, where most of the POLs are commercialized, the answer is negative. The POLs do not care about anything but making more money, which come from public exposure and supporters. So they have no motivation to argue against the trend at all. In fact, many POLs are known to intentionally start flamewars or spread falsehood messages to gain exposure.
Another interesting factor is the bots. It might be surprising, but a CMU research showed that the majority of the COVID falsehood messages on Twitter are spreaded by bots. And while I haven’t seen an academic research for the Chinese Internet, it’s undeniable that there are many keyword-based bots for various purposes (lottery, advertisement, promotion, PR manipulation, etc). It’s not surprising that there are similar falsehood message bots as well.
But what exactly went wrong? And how this might be fixed? Honestly I don’t know.
This is another note on JavaScriptCore (JSC)'s DFG JIT. The topic today is on DFG’s IR design and a related optimizer pass called CPS Rethreading. As before, disclaimer first:
Disclaimer
I do not work on JavaScriptCore, and my experience with Javascript is very limited. Everything described in this post is from my understanding of the JSC source code. They may be inaccurate or outright wrong. Please feel free to email me at haoranxu510 [at] gmail.com for any corrections and discussions.
In DFG’s IR, each function consists of a list of basic blocks, and each basic block contains a list of IR intructions. An IR instruction is also implicitly the value this instruction produces, and can be used as operand to other IR instructions. Everything till now is similar to a typical SSA representation. However, there are two important differences:
Each IR instruction can only use the SSA values (implicitly produced by other IR instructions) in the same basic block.
Unlike in SSA, DFG does not have an IR instruction named “Phi”. Instead, in DFG’s IR, each function has a list of “slots”, which are local variables that one can read from and write to. There are two IR instructions GetLocal and SetLocal[1] which allows reading/writing a slot respectively.
As one would expect, a GetLocal takes a slot number constant as operand, and produces an SSA value. A SetLocal takes an SSA value (i.e., an IR instruction that produces a value) and a slot number constant as operands, and produces nothing.
The above representation (called LoadStore form in JSC) is very flexible for users to generate the IR, but not good for optimization, because in such representation it is hard to reason about the data stored in local variables. This is where the CPS Rethreading pass comes in, which transforms the graph to the so-called ThreadedCPS form. The CPS rethreading pass optimizes away redundant loads, adds auxiliary Phi nodes that describe the data flow of loads and stores, and also performs liveness analysis.
The most interesting design choice here is that the Phi nodes are auxiliary and optional, and are not part of the IR graph: the correctness of the IR graph is not affected even if all Phi nodes were removed, and by doing so, it only puts the graph back to LoadStore form.
As a result, a transformation pass may choose to either maintain the Phi nodes and the liveness information, or simply mark that the graph has been put back to LoadStore form (and then the CPS Rethreading pass can be called to bring it to ThreadedCPS form again).
The extra information available in ThreadedCPS form is the following:
Each basic block gets a list of auxiliary Phi nodes. Unlike Phi nodes in SSA form, the Phi node here is parametrized by a slot number constant, so it denotes the value of that local variable at the start of the basic block. Those Phi nodes are only referenced by other Phi nodes (from other basic blocks) and by the stuffs below. They are never used by a normal IR instruction as operand.
Each basic block gets two auxiliary arrays variablesAtHead and variablesAtTail of length N (where N is the total number of local variable slots of the function). The variablesAtHead array denotes the value of all live variables at the start of the basic block. The variablesAtTail array denotes the value of all available (defined here as either live at the start of the basic block, or modified inside the basic block) variables at the end of the basic block.
Each GetLocal node gets an auxiliary pointer which denotes the value this GetLocal would yield. The pointer points to either a value-producing instruction in the same basic block (which means the GetLocal would yield that value), or a Phi node in the same basic block (which means the GetLocal would yield the value of the Phi).
Redundant GetLocals to the same local variable in the same basic block are removed. There are two cases:
(a). A GetLocal after another GetLocal can be replaced by the previous GetLocal.
(b). A GetLocal after a SetLocal can be replaced by the operand of the SetLocal.
There are a few points that are worth to note:
Point (2) above implies that the total space consumption is O(NM) where N is the total number of local variable slots and M is the number of basic blocks.
Redundant SetLocals to the same local variable inside the same basic block are not removed. Probably it has something to do with OSR.
The design above makes sure that all the extra information (most notably, the Phi nodes) are auxiliary: they can be safely dropped without affecting correctness.
The Algorithm
The algorithm is implemented in DFGCPSRethreadingPhase.cpp. For simplicity, as before, we will focus on GetLocal and SetLocal only, and ignore Flush, PhantomLocal, SetArgumentDefinitely and SetArgumentMaybe related logic.
The first step of the algorithm resets the existing state in case the pass has been invoked earlier. It clears the variablesAtHead and variablesAtTail array for each basic block, removes all Phi nodes, and reserves the space for the annotation pointer for each GetLocal node (by simply repurposes the unused child1 field).
In the second step, for each basic block, it iterates all the IR instructions from up to down. The variablesAtTail array is used as a scratchpad to keep track of the current value of each variable at the current IR instruction being iterated.
If it is a GetLocal instruction, and variablesAtTail[i] is nullptr, then this is the first time the variable i is used in this basic block, and the value of this variable should come from a Phi node. So we create a Phi node and store it into variablesAtHead[i]. The variablesAtTail[i] should also be updated to the current GetLocal node[2].
If it is a GetLocal instruction, but variablesAtTail[i] is not nullptr, then the local variable i has been used in this basic block. Thus, this GetLocal can always be removed from the graph by replacing it with another node (with detail described earlier). Thanks to the design of the IR, this GetLocal may only be used by later IR instructions in the same basic block, so the replacement can be done easily[3].
If it is a StoreLocal instruction, then we can simply update the corresponding slot in variablesAtTail.
The third step builds the incoming edges for all Phi nodes. The Phi nodes created in the previous step are put into a list[4]. The algorithm iterates until the list gets empty. Each time an element, let’s say, a Phi node for some variable i in basic block B, is removed from the list. Then for all predecessors P of basic block B:
If P.variablesAtTail[i] is nullptr, then there isn’t a Phi node in P for local variable i yet. So, a new one is created, and P.variablesAtHead[i] and P.variablesAtTail[i] is updated. The newly created Phi node is put into the list.
Otherwise, the predecessor of the current Phi node for that basic block should simply be P.variablesAtTail[i][5].
Note that the second step and the third step also guarantee that variablesAtHead correctly contains the information for all live variables at the start of a basic block.
Conclusion
In my opinion, the design of the DFG IR is really neat. The standard SSA form is best suited for optimization, but it is both difficult and slow to construct and transform. The DFG IR made interesting design choices that intentionally deviates from the standard SSA form to improve compilation speed and usability. This matches DFG JIT’s design goal as a fast optimizer. The CPS Rethreading pass is a neat algorithm that serves multiple purposes simultaneously: to simplify and canonicalize the IR, to construct a SSA-like Phi data flow, and to perform liveness analysis.
Footnotes
In fact, there are also Flush and PhantomLocal which are related to OSR, and SetArgumentDefinitely and SetArgumentMaybe which are related to special casing of arguments, but we will overlook them in this article for simplicity. ↩︎
It seems like the algorithm intentionally updates it to the GetLocal node instead of the Phi node because it can provide more information to users: one can easily trace to the Phi from the GetLocal but not otherwise around. ↩︎
Specifically, all we need to do is to maintain the replacement map, and at the time we iterate a node, we check if any of its operands are in the replacement map. If yes, we replace it. The replacement map can simply be a std::map, but a hash table lookup is still slow, so in JSC there is a 8-byte scratch field in each Node struct that can be used for this purpose (or other similar purposes). ↩︎
In fact, there are three different kinds of local variables: Argument, Local and Tmp. So correspondingly, there are three different lists. I think it’s only an implementation detail: the three list could have been merged into one, but the current code design (where the Kind is used as a template parameter in several APIs) makes it easiest to just have three lists. ↩︎
The actual implementation is a bit more complex. If the predecessor node is a GetLocal, it would further forward it to the value of the GetLocal (as computed in the auxiliary pointer), but if the predecessor node is a StoreLocal, it won’t forward it to its operand. But these are only implementation details to best fit the needs of the clients (the other optimization passes), so we omit them to highlight the core idea. ↩︎
Recently I’ve been spending time to understand some internals of JavaScriptCore (JSC), the Javascript JIT compiler powering the Safari browser. For background knowledge, I strongly recommend this great article from WebKit blog for a detailed overview of JSC.
This series of posts attempts to dive deeper into a specific area of JSC: the static analysis passes in JSC’s DFG JIT. Since Javascript is a highly dynamic langauge, it is critical to obtain as much type information as possible to better understand program behaviors so optimizations can take place. In JSC, static analysis is the primary tool for this purpose.
The WebKit blog article gave a good overview of the analysis passes. However, since static analyses are hueristic algorithms, the concrete algorithm design is as important as (if not more important than) the high-level idea to yield a working solution. I’m also curious about the other static analysis passes performed by JSC that are not covered in the article.
So I decided to dive into the implementation to get a better understanding of the full picture. This turns out to be much harder than I expected, primarily due to the lack of comments in the codebase. So I’m taking notes here for future reference.
Disclaimer
I do not work on JavaScriptCore, my experience with Javascript is very limited, and I do not have prior experience on static analysis. Everything described in this post is from my understanding of the JSC source code. They may be inaccurate or outright wrong. Please feel free to email me at haoranxu510 [at] gmail.com for any corrections and discussions.
Specialized DFG IR Node Type
The first optimization is not an optimization pass, but happens when the DFG IR is generated from the source-of-truth bytecode. For certain operations, there exists a specialized version of IR node type in addition to the general version. For example, ValueAdd handles the general addition that makes no assumption on operand types, while ArithAdd handles the case where both operands are statically known to be numbers (e.g., not String or BigInt or Object).
The logic that selects between the two versions can be found here. As one can see from the code, if the IR node types for the two operands both always return Number result (the IR node type list maintains what each node type may return), then an ArithAdd is emitted instead of ValueAdd. Since this is before any analysis or optimizations are run, there isn’t anything fancy here: all it checks is the IR node type.
Side notes:
I found this diff, which introduced the ValueSub opcode, quite helpful to understand what’s going on here.
I wasn’t able to figure out why the criteria for selecting ArithAdd is op1->hasNumberResult() && op2->hasNumberResult(). The if-check rules out result types that are more precise than Number (e.g., Int32, Int52 or Double), but I can’t see the reason to rule out such cases.
The backward propagation pass computes five flags for each DFG IR node. The flags are stored as part of [the NodeFlags field]((https://github.com/WebKit/WebKit/blob/8d5e5fd60f0712a47548a3b84c397836c481db75/Source/JavaScriptCore/dfg/DFGNodeFlags.h) in each node. The definitions for the five flags are listed below, as per comments in the code:
UsesAsNumber: whether the node result may be used in a context that observes fractional, or bigger-than-int32, results.
UsesAsOther: whether the node result may be used in a context that distinguishes between undefined and NaN.
NeedsNegZero: whether the node result may be used in a context that distinguishes between +0 and -0.
UsesAsInt: whether the node result may be used in a context that prefers (but not requires) int values.
UsesAsArrayIndex: whether the node result may be used in a context that strongly prefers int values.
For the first three flags, not setting a flag that ought to be set is a correctness issue.
For example, if the flag UsesAsOther is not set, but a node x is actually used in a context that distinguished undefined and NaN (e.g., x + "123"), then the program may be misoptimized, and the user may observe unexpected result for that computation (e.g., getting "NaN123" instead of "undefined123").
The NeedsNegZero flag seems (based on this bug report) to enable some -0 related optimizations. For example, a + (-0) can be optimized to a by speculating a to be not -0. The speculation is usually worth because -0 is rare, but it’s better to not speculate at all: if a + (-0) is part of a larger expression, and we can prove that even if a + (-0) were -0, the result of the full expression would be the same as if it were 0, then we can omit the speculation. One example where speculation a != (-0) can be omitted is (a + (-0)) + 1, and one counterexample where speculation a != (-0) is required is 1 / (a + (-0)). This is what the flag tries to determine.
The UsedAsNumber flag, based on my guess (from this commit), is designed to enable a special Javascript-specific optimization: Javascript bit-operators cast input to int32 and also outputs int32, so certain overflow checks can be eliminated if the output is fed into a bit-operator (for example, in (a + 1) | 0, if a were speculated as an int32_t, the overflow check for a + 1 may be omitted). It’s pretty tricky as seen from the related code and I can’t fully understand how the logic and optimization works. Given also that it seems to be a Javascript-specific optimization, I will overlook this flag below.
For the last two flags, however, not setting a flag that ought to be set is merely a performance issue and does not affect correctness.
The motivation for UseAsArrayIndex flag is that the conversion from a double to int is an expensive instruction, and since it is used as array index, it could be inside a loop and cause a big performance impact, so we should avoid this bad case if possible.
The Algorithm
In the initial state of a node, all the five flags are not set. The backward propagation pass is executed to set up the five flags (and it must set the first three flags correctly for correctness).
The backward propagation pass is a monotonic process. Each flag may only be switched from unset to set, but not the other way. This makes sure that a fixed point (where further execution of the pass can result in no state changes) is guaranteed to be eventually reached. However, this also means that if at one point we set a flag which condition actually never happens in reality, there is no way to undo the bad decision.
The pass iterates until the fixpoint is reached. In each iteration, it does the following:
Iterate each basic block in reverse order.
Iterate each IR instruction node in the basic block in reverse order.
For the current IR node, use its flags to update the flags of its operand (i.e., children) nodes. The concrete update logic depends on the node type, and is handwritten.
Since there are close to 400 different IR node types, for correctness, the default operation (for a node type not handled in the switch-case) is conservative: it sets the first three flags in all its operands.
As another conservative measure, even for node types that are explicitly handled, the default flags to propagate is the flags of the current node. So flags are propagated all the way down by default, and only stopped when the logic is explicitly written to not propagate a flag.
For ArithAdd, since we already know the two operands must be Numbers, it’s safe to not set the UsesAsOther flag for its operands. And if at least one of the operands is known to be not a -0, then the result of the add must not be a -0 as well, so the -0 in the operand will not be observable after the add, so in this case it’s safe to not set the NeedsNegZero flag for both operands.
ValueAdd is similar to ArithAdd, except that it may take non-Number operands. In that case, undefined and NaN in operand may be distinguished (for example, in x + "123"). Therefore, for ValueAdd, the UsesAsOther flag is only not propagated if at least one of the operand is known to produce numeric results (in that case, if the other side is undefined or NaN, the final result is always the same, so the two are indistinguishable). Note that such criteria is not complete (sufficient but not necessary): but this is as far as static analysis can go.
Side notes:
I couldn’t fully understand the purpose or implementations of the UsedAsNumber flag. Any explanations would be welcomed.
The pass did not handle operators like ValueSub, ValueMul, etc. It seems to me the developers forgot to update the pass when those operators are introduced.
One interesting thing is about the “conservative” measures implemented in the code to reduce the risk of correctness bugs. If my interpretation that the devs forgot to put ValueSub, ValueMul, etc. into the pass is correct, then on one hand, the conservative measures indeed prevented a correctness bug. But on the other hand, since no correctness bug is produced, it would take a long time to figure out that the pass has become outdated and has been silently producing suboptimal results.
A while ago I had been co-lecturing a small group of OI students with Richard. I was impressed how he could just take over any talk on anything, and he said:
A professor is someone who can talk on any topic for 90 minutes.
Well, although I have no idea if I want to (or can) become a professor, talking skill is definitely something useful to learn, as I increasingly recognize its importance.
Recently, I had the opportunity to pitch my works to quite a few people (well, that’s actually a lot of people conditioning on that I am so introvert and most of my interactions are limited within a few people). So I decide to write down some experiment notes for future reference.
After some reflective thinking, I categorized my experience as following:
Talking with technical engineers in the same field.
Talking with technical engineers.
Talking with people who do not do engineering themselves.
Interestingly, my experience is that talking to people in the second category is the hardest.
Talking with people who do not do engineering
A while ago I talked to two startup founders who used to do engineering, but have since transitioned to management roles. It seems like they are most interested in the product side of the story, i.e., the impact of my work on the end product and the end users. They are also interested in the high level technical ideas, but they are happy to overlook any technical detail that they cannot immediately understand.
So it seems to me the important things for such talks is to highlight the motivation and the end results, i.e., convince the audience that my stuffs are practically useful. The high level “how it works” explanation more serves as a method to clear their doubts: they want just enough technical ideas for them to perceive the work and the results as “reasonable”, but not any more detailed than that.
There is one interesting failure to note. During one of the talks, I mentioned my dynamic language JIT constructor idea, and get asked: “The most dominant dynamic language is Javascript and is already well-optimized. Every other language is decading in the market. Why do you want to optimize for dying languages?” I apparently didn’t anticipate this question, and I have never paid attention to the market occupation rate of the langauges. So I had to go hand-waving and say that there are still many existing use cases, and it’s unlikely that they will die out any soon. If I had researched a bit about the market occupation rate, I would have known that his argument on the language market is simply incorrect and produced a better answer.
So another lesson is that since their focuses and views are different from technical engineers, they may ask unexpected questions. But I don’t see a good solution to handle such situations in general.
Talking with technical engineers in the same field
It seems to me these talks are the only cases that I should really elaborate what I did. So probably there’s not much strategy here: all I should do is to introduce the motivation and the results, then elaborate my idea as clearly as possible, and take feedback.
One thing that surprised me is that during a presentation to Google Dart team, a slide containing the assembly my compiler generated attracted a lot of attention. They are actually looking into the assembly to get a better idea on what I did. Not sure how general it is, but it seems like I might have underestimated how much technical detail the audience is willing to dive into.
Talking with technical engineers outside the field
This is where most of the failures come from. If I were to summarize, I feel the main reason is that they want to understand how my stuff precisely works from end to end, but the background differences make explanation difficult and confusion easy.
The biggest failure was in one job interview in which I tried to explain to the interviewer some data structure research I did. I tried to introduce my algorithm by first explaining how x-fast trie (which my algorithm is based on) works. The outcome is clear: the interviewer was completely confused and asked more and more questions, and I didn’t even get into the novel things I did before time run out.
A few smaller failures also happened during the other interviews for that job. The situations were pretty similar. The interviewer gets interested at some particular detail of how my stuffs work, I explained but only to make them confused, and I wasn’t able to make them understand before time runs out. I was also a bit skeptical on how much they really understood what I tried to convey. It’s likely that they are confused much earlier than they speak out that they couldn’t understand something.
But unlike the people doing management, engineers won’t be satisfied by only knowing the motivation and the results (this is why such failures only happen when talking to engineers). So it seems to me the lessons are the following:
Be very detailed in terms of the problem and the assumptions, i.e., make it very clear on what I have in hand, what I am trying to solve and what I am assuming. A seemingly-obvious assumption could be not obvious at all for someone with a different background.
But, stay away from all technical details. Explain everything in high level. It’s probably even worth to explain everything by analogy. If they ask about technical details, probably the best answer is to just say it’s going to take too long to explain, and try to answer the question using an analogue.
Get a good estimation on how much time is needed to explain a certain thing in a certain level of detail. For example, it might take 60 minutes to make a normal engineer understand x-fast trie, so doing this in an interview is doomed to be disastrous.
A few other failures
Once I tried to convince Richard that a Halide-like approach might be helpful to implement some of his crazy algorithms. It didn’t end up well because I didn’t know Halide that well and I had to think while talking, which turns out to be amazingly hard. In general, I feel it very hard to think about any logical stuffs while talking, so probably it’s best to avoid that.
Another stupid failure happened in a poster session. I underestimated the weather and trembled in the wind as a result. The lesson is clear.
Summary
It seems that the common parts above is about the right level of technical details. It is beneficial to present in detail when the audience are people in the same field. However, it seems like in other cases, getting into technical detail is a major source of failures, and should be avoided as much as possible. However, obviously, this is only the conclusion drawn from a few experiences.
Yesterday I got into the following problem. I want to allow certain C++ struct definitions in my code to be reflectively inspected. For example, if I defined a struct S with two int fields a and b, the other parts of my program should be able to know that the struct S contains such two fields with such definitions and can act upon this information.
Trivially, one can solve this problem by maintaining two pieces of code: the original definition and a map like { 'a': 'int', 'b': 'int'}. But then the two pieces of code must be manually kept in sync, which is the point I want to avoid.
Such use case is known as reflection. Unfortunately the C++ standard does not have native support for reflection. There are paper proposals to support it, but none of the major compilers seem to have implemented them yet.
The problem can also be solved via a huge hack called “the C++ Type Loophole”. However, it’s unclear why the hack could work, and it’s so hacky that even the C++ standard committee has reached a decision that it should be prohibited. So I’m not brave enough to use this hack.
I eventually reached a less hacky (but of course, less powerful) solution. Since there is no native support for reflection, something has to be instrumented into the definitions of the structs. So in my solution, to make a struct reflective, one must use special macro FIELD(type, name) to define the fields: this allows us to automatically add some instrumentation into it. An example is shown below.
My trick is based on the C __COUNTER__ macro. __COUNTER__ is a special macro that each time it is encountered, it is replaced by the current value of an internal counter maintained by the compiler, and then the internal counter is incremented. So each __COUNTER__ macro is replaced by an unique integer that monotically increases through each occurrance in the program text.
Note that the __COUNTER__ macro is replaced on the spot. For example, a ## __COUNTER__ = a ## __COUNTER__ + 1 will not increment the variable, since it’s going to be expanded to something like a1 = a2 + 1. So the common use pattern of __COUNTER__ is to pass it to another macro as a parameter, as shown below:
1 2
#define MY_MACRO_IMPL(a, b, counter) ... my impl ... #define MY_MACRO(a, b) MY_MACRO_IMPL(a, b, __COUNTER__)
This way, the MY_MACRO_IMPL macro can use its counter parameter as an unqiue integer.
The core of the trick is to use this __COUNTER__ macro to specialize templates. For a simple example, let’s assume we want to define structs that we can reflectively retrieve the number of fields in the struct. Then BEGIN_FIELDS_LIST can expands to the following code:
The BEGIN_FIELDS_LIST will define the general case of a template specialized by an integer o. The general definition will simply inherit whatever information is computed by template o-1. In addition to that, it also defines the recursion boundary condition (in our example, since we want to count the number of fields, N = 0).
Each FIELD defintion specializes __internal<__COUNTER__>, and computes its information by merging the results in counter-1 and itself (in our example, N = __internal<counter-1>::N + 1).
END_FIELDS_LIST can retrieve the aggregated results in __internal<__COUNTER__>.
As one can see, the correctness of the above approach relies on only that each counter is replaced by a monotonically increasing integer. The starting integer value, or if any integer is skipped in the sequence, do not affect the correctness. And this matches exactly the semantics of the __COUNTER__ macro in C. So are we good?
One tricky problem arises from translation units. C/C++ compiler works on translation units (C/C++ files). So if a header file containing our definition is included by multiple source files, we may get different counter values in different translation units. In other words, the __internal struct is specialized differently in different translation units. This doesn’t affect our correctness. However, the important thing is that this violates C++'s one-definition rule.
Fortunately, we are not doomed. C++ standard specifies that a constexpr symbol is only emitted if it is used by non-constexpr code. Since the __internal structs are only used to compute our final constexpr result __numFields, the compiler is guaranteed to not emit anything about the __internal structs. So no violations of the one-definition rule can be observed. And if we need to add non-constexpr functions to the __internal struct, we can also mark it as always_inline (which tells the compiler that the function must be inlined for correctness) to make sure nothing about the __internal structs are emitted.
So to conclude, as long as we make sure that the __internal structs are not used elsewhere other than computing the final results (which can be achieved by, for example, making all its members private and all its non-constexpr functions always_inline), we should be fine with C++'s one-definition rule requirement.
Today I got into a question loosely related to my research. Many language VMs choose to implement their own call stack, instead of piggybacking on the native C stack. Probably one advantage of such non-native stacks is that it makes implementing coroutines and stack walking easier.
But this is not my question. Everyone knows in C function calls are implemented by the call instruction and the ret instruction. These machine instructions implicitly modifies the SP stack pointer register and then redirect the control flow. So if we were to use a non-native stack (that is not managed by the SP register), the straightforward way is to simulate the call and ret by jmps. However, a ret is actually an indirect jump, since it jumps to non-literal address (the return address).
It is well known that indirect jumps are slow, since the jump target is hard to speculate, and if a CPU fails to speculate, it fails to run fast. So my question is:
How much slower is an (inpredictable) indirect jump compared with a ret?
Unsurprisingly, modern CPUs extensively optimize ret given its pervasive use, through a specialized branch predictor called a Return Address Stack (RAS). That post also measured various hardware-specific limits of the RAS, and demonstrated the extraordinary performance punishment if a user program made the RAS unhappy. However, it did not measure how an impredictable indirect jump compares with a ret.
So I decided to experiment with it myself. The idea came off my head is the recursive Fibonacci function. Since it has two recursive calls, a ret simulated by indirect jmp will have two possible targets. Importantly, the pattern of which target being taken is complex and it is unlikely that a CPU can predict it.
So I wrote a simple recursive function using the C native stack, and a hand-rolled function using a custom stack. For the hand-rolled function, a recurse is implemented by a goto, and a return is implemented by a computed goto, using the GCC computed goto extension feature, with the key logic shown below (full benchmark code).
structStackFrame { void* ret; int n; uint64_t tmp; };
// key logic // stacktop is a StackFrame* entry: n = stacktop->n; if (n <= 2) { ret = 1; goto *stacktop->ret; } stacktop++; stacktop->ret = &&after_call1; stacktop->n = n - 1; goto entry; after_call1: stacktop--; stacktop->tmp = ret; n = stacktop->n; stacktop++; stacktop->ret = &&after_call2; stacktop->n = n - 2; goto entry; after_call2: stacktop--; ret += stacktop->tmp; goto *stacktop->ret;
One tricky part is that GCC is smart enough to unroll the Fibonacci function into a single recursive call performed in a loop. We do not want this to happen, since the point of this microbenchmark is to have two call sites. Fortunately, by compiling with -O1, GCC won’t perform this unwanted optimization. I also confirmed that the assembly code generated by GCC correctly replicates the computation logic I wanted to test, as seen below.
I ran my microbenchmark code to compute fib(40)=102334155, and the result is as follow:
NOTE! THIS IS NOT VALID RESULT! Keep reading.
Custom stack (computed goto) took 0.301 seconds.
Native stack took 0.266 seconds.
So it seems like the non-native stack incurs about 10% overhead for Fibonacci: I know this is not a very accurate measurement, but I (naively) felt that it is good enough. So I decided to clean up my code a little bit for future record. Of course, the story is not that simple…
So, I decided to add a printf in the main function to make the output more informational. Of course, the printf is outside the benchmark timing region. Specifically, all I did is adding the two printf lines, exactly as shown below:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
intmain(){ >>>>> line added >>> printf("Benchmarking Fib custom stack..\n"); uint64_t result; { AutoTimer t; result = FibCustomStack(40); } printf("%llu\n", static_cast<unsignedlonglong>(result));
>>>>> line added >>> printf("Benchmarking Fib native stack..\n"); { AutoTimer t; result = fib(40); } printf("%llu\n", static_cast<unsignedlonglong>(result));
return0; }
I compiled and ran the code again, not expecting any changes in numbers. What astonished me is that my computed goto implementation went from 0.30s straight up to 0.34s!
Something clearly went wrong. But what could go wrong by adding two lines of printf? And the printf is not even in the code being timed!
I first tried to increase the input from 40 to 45 so the benchmark computation runs longer. It turns out that, without the additional printf, the computed goto implementation took 3.4s. But with the printf, the time increased to 3.9s. So the slowdown is not even a fixed slowdown, but scales with input! WHAT?!
Okay. So what if I delete one printf? I tried to delete the first printf, so the benchmark in question is executed first, and then the extra printf is executed. However, the 3.4s vs 3.9s slowdown is still there. How come this extra printf can slow down something that is executed before it?!
I decided to dump out the full assembly and compare line to line.
Surprisingly, and not surprisingly, the two versions are identical – except a few more lines of assembly at the expected spot that calls the extra printf. I am completely baffled.
Fortunately, even though I’m not sure if deities exist, I am skeptical that there is a deity who is responsible for my CPU’s performance. I soon realized that the code layout must have been changed by the extra printf. So I printed the pointer address of my function FibCustomStack. Indeed, the pointer changed from 0x****190 to 0x****1a0 (the higher digits are inheriently random due to ASLR).
Though I’m not a hardware feature expert, I still know that the CPU branch predictor works by hashing some bits in the address. The change in function address clearly also changes the address of all branch targets. Is this what caused the slowdown?
Fortunately this hypothesis is easy to validate. The FibCustomStack function can be easily modified to not reference any global variables/functions, and thus made trivially relocatable. Then, we can relocate this function to different addresses, and check for any change in performance.
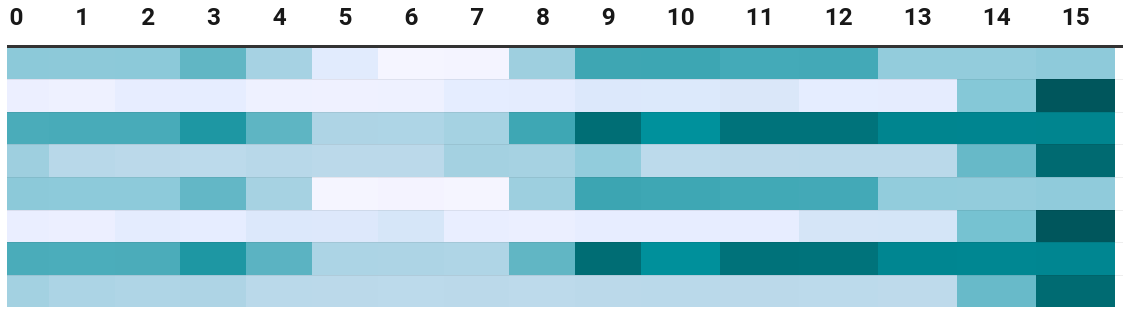
I wrote a simple program to test this hypothesis (Note: the program is architecture-specific. My CPU is Intel Core i7-7700HQ CPU @ 2.80GHz. The program may or may not run on another CPU). It mmaps a memory region as executable, and copies the binary code for the FibCustomStack function to different offsets in the region, and tests its performance. The program currently only test different offsets of the lowest 7 bits (128 combinations), but changing this behavior is easy.
To plot the result, the execution time corresponding to the 128 offsets (raw data) are plotted into a 8x16 matrix, with the 16 columns denote the value of the lower 4 bits of the offset, and the 8 rows denote the higher 3 bits. The matrix is then plotted as a heat map: a darker color means a slower execution time. The fastest of all 128 values is 3.33s while the slowest is 4.54s: almost 50% slower than the fastest.
Somehow counter-intuitively, the function address that yields the fastest execution is not a multiple of 8 or 16. As a note, the function itself is compiled with -falign-functions=16 -falign-labels=16, so the offset between all branch targets and the function address is a multiple of 16. GCC treats it as an optimization to align functions and labels to power-of-2 byte boundaries, but this has been proven by the above heatmap to be not always beneficial. Therefore, the actual search space of code layouts is even larger: not only the higher bits of the function address (that is not tested by our simple program) may matter as well, but also internally, the function may arrange its branch targets at different (and not necessarily multiple-of-8 or 16) addresses to make the branch predictor’s hash function happy.
Another counter-intuitive observation from the raw data is, certain function addresses (especially the slow ones) make the execution time much less stable than others, as shown in the stddev tab. I can think of no explanation why such macro-scale fluctuations can happen.
I’m sure someone who knows more about hardware details than I do can explain better. If you have more ideas on what’s happening here, I’d really appreciate if you could send me an email (haoranxu510 [at] gmail.com)!
Conclusion
Although the experiment is still far from complete, the data collected as of now is already sufficient to disqualify the usefulness of the initial microbenchmark. While seemingly completely valid, it turns out that all we are testing is the performance at a random point inside a huge state space that is coincidentally thrown to us by the compiler.
It’s worth mentioning that the problem is not fixed even if the said microbenchmark were implemented in assembly: even in assembly, you cannot easily specify the address of your function. And due to ASLR, the higher address bits of your function is always unknown. And if the CPU branch predictor hashes physical address instead of virtual address (I don’t know if it’s true or not), then you cannot control your function address even with ASLR disabled.
Therefore, this demonstrates a case where even the expressiveness of C or assembly is not low-level enough to get sensible microbenchmark results. Furthermore, it is extremely easy to get misleaded: how counter-intuitive it is that the function address of your function can cause a up-to-50% performance impact!
So, I witnessed again the complexity of modern CPUs, and the difficulty of the attempts to “capture” its behavior through microbenchmarks.
P.S. During the experiment, I also hit a GCC miscompilation bug (repro) caused by its computed-goto extension. The comment in my repro explains what happened. I’m not fully certain if my code is completely UB-free (I’m not language standard expert), but I guess I will still limit my trust in the GCC computed goto extension as a result.
I used to maintain a blog while I was in high school, like many others who have participated in Olympiad in Informatics did. I had been used to posting solutions to competition problems I encountered, interesting algorithms I learnt, and slices of my life experience. Yet, also like most of them, I blogged less and less frequently as I entered college, and before too long, I stopped blogging completely.
The precise reason that a blogger stops posting probably varies from person to person. Retrospectively thinking, the reason for my case is not that I am no longer learning new stuffs in college thus having nothing to post. Instead, I was learning a lot. However, I was hardly able to get much new insights from the stuffs I learnt. If Olympiad in Informatics is about creatively making use of the knowledge one have learnt on new problems, then I guess, during my undergraduate years, I have learnt a lot more knowledge, but I did not learn how to creatively apply those knowledge to produce something new – and by parroting theorems, theories and long proofs verbatim, one clearly cannot make an interesting blog post. Even worse, knowledge fades away in time. I don’t think I still remember anything taught in the hardcore math and TCS classes I took at MIT.
This is a hard lesson learnt in the hard way. I hope that by writing this down into a blog post, and by keep posting about what I have learnt (which makes sure that I am getting some insights from it), I can often get reminded to not get into the same pitfalls again.
There are other reasons as well. I saw by chance this amusing but thought-provoking post by Manuel Blum, and his argument on the importance of writing with this interesting “proof”:
You are all computer scientists.
You know what FINITE AUTOMATA can do.
You know what TURING MACHINES can do.
For example, Finite Automata can add but not multiply.
Turing Machines can compute any computable function.
Turing machines are incredibly more powerful than Finite Automata.
Yet the only difference between a FA and a TM is that
the TM, unlike the FA, has paper and pencil.
Think about it.
It tells you something about the power of writing. Without writing, you are reduced to a finite automaton. With writing you have the extraordinary power of a Turing machine.
as well as another blog post by Matt Might on the importance of practicing writing for graduate students. Having been struggling with writing out academia-paper-grade paragraphs recently, hopefully I can improve my writing skills a little bit by posting >_<.